Modern Strategies for Data Curation in Computer Vision
March 16,2023Creating datasets for the modern AI workflow

AI systems are extremely powerful. But when they fail, they often mess up spectacularly.
Adding physical stickers to street signs can cause AI misreadings. 3D printed heads can fool face recognition systems. We’ve recently discussed AI racial and gender bias in a previous post. Unsurprisingly, most of these failures stem from underlying issues with training and testing data.
That said, AI remains an extremely powerful technology if we can overcome these technical hurdles. If you need your AI models to be robust, high-coverage, and unbiased, data curation is absolutely essential.
Once overlooked in favor of optimizing AI models, data curation is garnering attention as developers shift towards the data-centric AI paradigm and focus on building high-quality data for AI training and testing.
Data curation, in context of the modern machine learning workflow, refers to automatic or manual optimization, structuring, analysis, tagging, filtering, and sorting of training and testing data.
The ability to control dataset content is one of the biggest driving factors in getting the desired behavior from your AI models. With a solid curation methodology, we’re able to transform huge, unstructured data into controllable, diverse training sets and highly specific diagnostic test datasets.
Better data curation = feature creation
After you've collected data, you'll need to organize and optimize it for AI training and testing. The big objective in modern data curation is to increase the usefulness of your data by organizing and transforming data in a way that is most likely to improve your models.
In this vein, curation can be thought of as using or creating data feature “columns” for samples to make searching and grouping easier and more impactful. Better features mean more targeted and accurate sorting, which translates to better curated training and testing datasets.
For computer vision, metadata and features such as image composition, scene lighting, view angles, and sensor parameters can be collected or computed.
Existing metadata, together with class and object labels, can be used individually or combined to create slices, groups of samples that share common traits. A particular data sample might belong to multiple slices.
By isolating data slices, we can train on specific subsets of data, and analyze model performance and failures and attempt to solve them in the future.
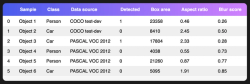
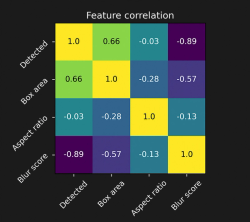
Consider the above validation set. Creating and computing new feature columns such as "box area" and "blur score" is extremely useful since it allows us to trace the cause of failures: in the above case, it indicates a possible failure on a slice of small and blurry objects, rather than a specific class or image source.
What are your options to curate datasets?
Curation through hand-labeling attributes
Curation can be executed manually by tagging data samples by hand with new features, or formatting and/or combining existing labels or metadata. After we've obtained an initial model result (e.g. the validation table above), we can measure the correlations of one or multiple features with model successes or failures.
Pros
- Semantic variables (e.g. “realism” or “difficulty”) can be labeled by humans
- High degree of control over feature quality and design
Cons
- Requires defining a static set of metadata beforehand
- Subjective from one individual to another
- Hard to do at scale and suffers from the same issues as data labeling
Curation through collecting and creating metadata
We can also existing metadata to group samples in new ways. New metadata can be created from combining or filtering existing fields.
Consider the case where we're working with image sensor data, which often has timestamps. One trick is to compute new features (e.g. “season”) from existing metadata (e.g. “timestamp”), and slice the data that way.
Curation can be made easier with simultaneous metadata collection. For example, satellite imagery typically comes tagged with attributes such as collection timestamps, ground sampling distance, elevation angle, and location; while autonomous vehicle data can be collected with location coordinates, vehicle speed and trajectory, and vehicle instrument readings.
Pros
- Simple data engineering once metadata is acquired
- Features can be combined any time, not just during collection and curation
Cons
- Metadata is only available for specific sensors and hardware (e.g. satellite, automotive)
- Metadata is not exempt from noise, errors, and data quality issues
Curation driven by image processing
For image data, we have the luxury of leveraging image processing techniques to compute features, such as luminance, average color, edge maps, blur (via variance of Laplacian), SIFT and HOG features, and frequency analysis to break down image content.
Images can then be organized by the values of these features, and the distribution of images in the datasets with respect to these features are revealed.
Pros
- High explainability, since image features are semantic (e.g. blurriness)
Cons
- Not all image content can be explained by simple image processing. It can be difficult to extract some meaningful features, such as the shape and orientation of objects
- Requires basic to intermediate image processing expertise
Curation driven by neural networks (direct prediction)

In a similar vein, we can train vision networks to infer properties about image samples. For example, we can train a land-cover classification model to tell us the biome of a satellite image, or an object detection network to tell us the types of boats in the sea.
There are commercial image tagging solutions available, but the quality of these solutions has yet to be rigorously tested.
Pros
- Retains explainability of features
Cons
- Requires resources to label data
- Predictions can be noisy, or incorrect
Curation driven by deep neural embeddings
Neural networks have layers that project images into useful representations. They act as encoders, transforming the input image into an intermediate representation. We can hijack the intermediate outputs of these layers to obtain embeddings that describe the content of image samples.
Different layers produce different representations that may be useful for filtering samples. For example, shallower embeddings could replace curation by image processing, while deeper embeddings could replace curation by auto-labeling.

Embedding vectors are often high dimensional, so using them directly as features can grow out of hand quickly. Dimension reduction techniques and clustering algorithms can help to simplify these embedding features.
Images or objects can then be curated based on their cluster memberships or similarity to other images directly in embedding space.
For further reading, check out this short explainer! We also recommend TensorBoard Projector, an amazing interactive tool to understand the power of image embeddings.
Pros
- Using the powerful representation capability of a vision network with no training or fine-tuning required
Cons
- High dimensionality means that further processing must be done to simplify the representations
- Embeddings can be noisy and heavily depends on how the encoder was trained
- Low explainability since embeddings can have no clear semantic meaning
Using data curation tools
As the data-centric wave hits the AI community, there’s been an explosion in data curation platforms. Vendors typically offer platforms to organize and analyze your data using one or more of the approaches mentioned above.
Vendors such as Lightly and Sama provide enterprise-level data curation platforms for data visualization, sorting, and filtering.
Pros
- Good data visualization tools
Cons
- Data curation-aaS platforms are generally not mature yet with respect to performance guarantees
- No fine-grained control of curation methods
Curation with synthetic data
At Bifrost, we’ve generated synthetic data for a plethora of environments and sensors, including geospatial imagery, desert, maritime, and urban imagery, and even Martian terrain.
We’ve worked with a mind-boggling amount of environmental parameters, asset attributes, and post-processing effects. The richness of metadata allows us to create slices easily and effectively to build diverse and high-coverage synthetic training and test data.

One of the best things about synthetic data is that we have absolute control over the content and distributions in your dataset. In other words, instead of curating data by computing its properties, you directly specify the properties of your data.
Synthetic data is therefore extremely powerful for unit-testing models on different slices, because those slices can be directly generated.
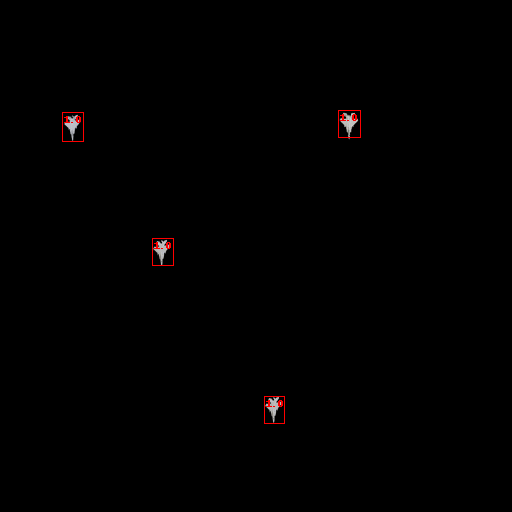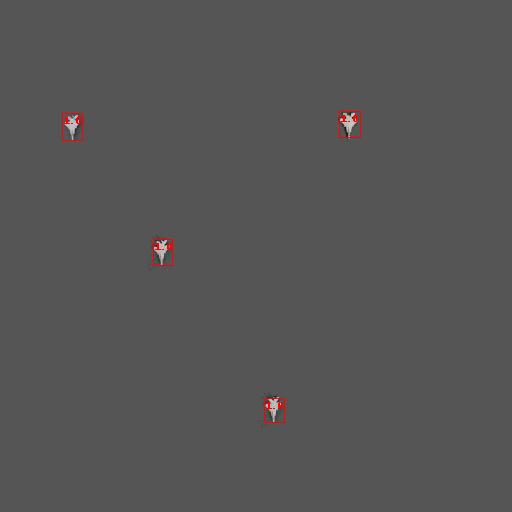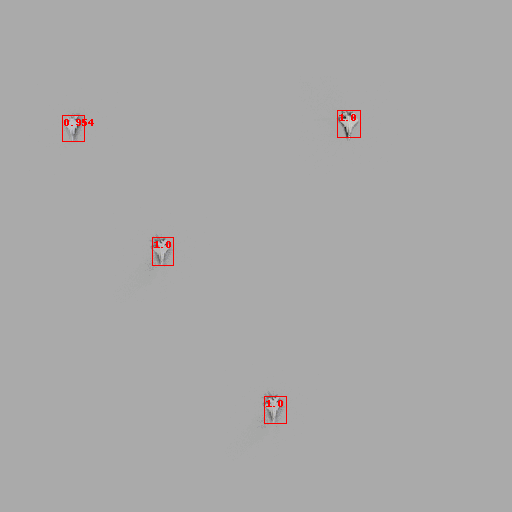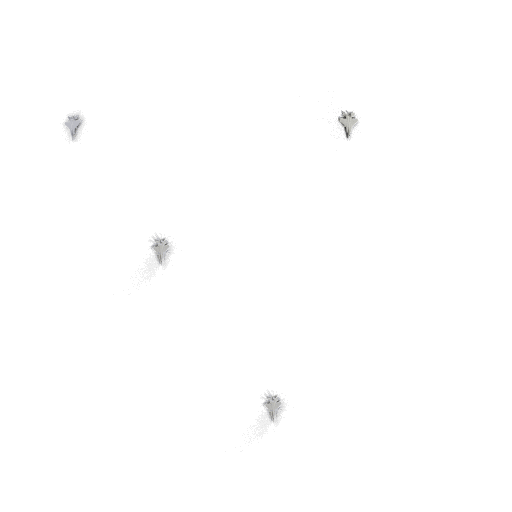
The above image shows a simple example testing across a particular image feature (the luminance of the background). Above a certain luminance, the model’s predictions start to lower in confidence and are pruned. With this information, we can then introduce more images with high-luminance backgrounds in our next training set.
Conclusion
What is data curation?
Organizing and transforming data in a way that is most likely to improve your models.
Why data curation?
- It allows you to scope your AI problem and define expectations for model coverage
- It allows you to design flexible model training schemes
- It allows you to evaluate your models on specific slices of data
- It allows you to fine-tune your models on specific failure cases
How to do data curation?
Use existing properties or compute new properties for your data samples, and use them to organize and group similar samples together to create better training and test datasets. Depending on your use case, manual or AI-assisted in-house solutions can work. Enterprise curation platforms are also available. Synthetic data is a powerful, increasingly popular option to bring data curation workflows to the next level.
Notes
Data slicing is an active area of research. For more information on slicing, check out recent research papers and articles:
FreaAI: Automated extraction of data slices to test machine learning models
Model drift detection via weak data slices
Slice Finder: Automated Data Slicing for Model Interpretability and Here









