Why Synthetic Data is the Unfair Advantage for AI
March 13,2023Introduction

In the last decade, we’ve seen AI create brand new industries to solve some of the world’s most critical problems. But building these capabilities, once considered impossible with traditional software, has since proven quite the uphill battle.
Compared to regular software, AI systems can take years to build, requiring a lot more resources and manual labor. Teams are spending millions of hours painstakingly collecting, sorting, curating, and labeling endless heaps of raw data. It almost feels like AI has created more work for us — and we’re the ones working for AI.
Data is Crucial in Building Great AI systems
Building AI requires two core components — the model and the dataset. The model takes in a dataset as input and learns from it. Once trained, the model is used to make predictions.
AI = Model(Dataset)
State-of-the-art models have become easily available to everyone. With minimal changes and fine-tuning, developers are able to achieve stellar results — if they have a great dataset to feed their model.
The adage garbage in, garbage out applies here: the quality of a dataset will make or break an AI system. If models are trained on biased datasets, they will make biased predictions. Datasets must be large and diverse for AI systems to handle different scenarios and edge cases.
Today, teams need to curate the best datasets by collecting as much diverse data as they can. They focus less on building algorithms, and more on coordinating large-scale and widespread data collection efforts. However, accomplishing this feat at scale turns out to be a lot harder than expected.
The Difficulty of Building Datasets
AI teams are still struggling with building datasets. A 2019 study determined training data volume and quality to be the largest barrier for machine learning, with 96% of respondents reporting data quality issues.
The problems were frustrating enough for 71% of teams to ultimately outsource collection, curation, and labeling. The same year, another developer survey found that data quality issues were encountered 95% of the time, which most considered critical and required high effort to address.
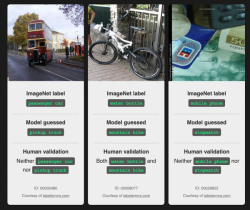
Public datasets are not exempt either. ImageNet, arguably the most prolific dataset of images, enabled modern image classification. Its initial release, with 3.2 million images, took 48,940 workers across 167 countries more than two years to sort and label. After a decade of labor, ImageNet today is still plagued by incorrect labels, biased samples and annotations, and privacy issues. Pictured here are examples of disagreements between ImageNet labels, model predictions, and human validation.
Collecting data can be the hardest part, and in some cases near impossible. The ideal dataset is diverse and balanced, containing a variety of objects in different contexts, lighting, and weather conditions.
While building such a dataset can be tricky, it is achievable with substantial time, capital, and infrastructure. But for certain tasks, acquiring those diverse samples can also be impossible — imagine having to scour satellite imagery of the entire Atlantic Ocean, attempting to gather thousands of examples of one specific type of ship that’s rarely seen.
Generating Virtual Worlds at Scale to Train AI
At Bifrost, we simulate virtual 3D worlds to capture data at a fraction of the time and cost, enabling teams to generate highly customized, perfectly labeled training datasets without resorting to manual collecting, sorting, curating, or labeling.

We’re focusing on being extremely good at generating and controlling virtual worlds, environments, and objects. We’ve also built the tooling to simulate cities, airports, forests, oceans, coastlines, and even other planets for a variety of AI tasks.

Since everything is virtual, we’re able to simulate an extremely large variety of scenes, objects, and conditions— including data of rare, critical scenarios, which can prove difficult to procure in the real world.
From these high-fidelity environments, we’re able to build diverse and performant synthetic data, used to train AI systems on tasks like autonomous navigation, object detection, and semantic segmentation. These performance-first sandboxes are perfect for AI to learn (and if necessary, safely fail) before venturing into the real world.
Synthetic Data is Already Showing its Edge
While synthetic data is computer-generated, it mirrors the structure and statistics in real data. Numerous studies have shown that AI models trained on synthetic data can match or surpass their real-data trained counterparts.
Even companies known for their troves of real data are turning to synthetic data.We’ve seen Tesla develop vast simulated cities to train self-driving cars and handle unexpected driving scenarios. Facebook (now Meta) built life-like synthetic indoor scenes to train home robots for visual navigation. Amazon’s cashierless store was trained to handle diverse human poses and scenarios through synthetic data.
As the cost, scale, and complexity of their deployments get larger, companies are finding themselves hitting the limits of what they can achieve with manual data collection and labeling.


These examples are the early signs of a larger trend. In the above Gartner projection, the dominant data being used for AI in 2030 will be synthetic — generated from rules, statistical models, simulations and other techniques. We certainly agree we “won’t be able to build high-quality, high-value AI models without synthetic data”.
But if synthetic data is such a no-brainer, why isn’t it the de facto standard yet? Well, for one, early synthetic datasets were largely byproducts of academic research, with limited fidelity and customization options. Even today, publicly available synthetic datasets lack realism while remaining highly task-specific, which means we can’t just drop them in as replacement datasets for specialized applications.

From Synthia (2014), to AirSim (2017), to Bifrost (2022) — the synthetic data field has seen leaps in progress. Given where we all started just a couple of years ago, and where we are now, we think synthetic data is fast becoming a critical, even standard, tool in building robust AI systems. We’re supporting this paradigm shift by building high-quality generation pipelines, tailored for AI and delivered at scale.
Wait, but What Does High-Quality Synthetic Data Mean?
Being good at synthetic data involves going beyond generating imagery that merely looks and seems real — we’ve made it a huge priority to understand the science behind its creation and its effects on AI models, as opposed to generating millions of variations of a scene via brute-force. Good synthetic data generation, we believe, has three major necessities:
The first characteristic of good synthetic data is its diversity of content (at Bifrost, we call this the mild-wild spectrum!) — describing the ability to generate a diverse amount of objects with different structures and materials, under a variety of lighting and weather conditions.
The second characteristic is the data’s domain similarity to reality, how closely it approximates real-world sensor data in terms of appearance, features, structure, noise signatures, and pixel-level artifacts.
Lastly, we believe that good synthetic data maintains granularity of control over the generation process, enabling customization for specific use cases and deployments. These environments leverage procedural content generation, custom 3D models, and elaborate user-defined distributions. Control allows the synthesis of precise samples you may need to deal with edge cases and rare, under-represented scenarios.
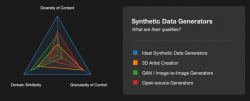
Synthetic data tooling often focuses on one of the three, but we’ve found that synthetic data starts to shine when we advance all three qualities: optimizing both diversity and domain similarity, while maintaining fine-grained control over the generation process.
Battle-Testing Synthetic Data
We’ve spent the last few years deep in research, refining our synthetic data approach and working with esteemed industry partners to battle-test our synthetic data against real-world data.
We’ve found that rather than generating tons of random images, it's really about iteratively building datasets using a data-centric approach — which happens to save time, effort, and a whole lot of computing resources. Done right, synthetic data allows us to match the order of data required for supervised deep learning and reinforcement learning, unlocking generalization capabilities beyond any real-world data one has on-hand.
Build Robust Autonomous Systems. Detect Rare Objects. Get the Edge You Need.
For decades, we’ve relied on simulations for engineering in the real world — stress-testing buildings and structures, or simulating traffic networks for urban planning. Now, as more machines enter our world, it’s more important than ever to begin simulating our visual world, with all its color and complexity, to build better and safer AI vision systems. Every day, we’re working towards blurring the boundary between simulation and reality — and when it blurs, those with synthetic data will truly have an unfair advantage.
Through our work and partnerships, our synthetic data has been used to supercharge AI development, train landing systems for Mars, and thwart pirates at sea. We’ll be sharing these case studies in our upcoming posts, so do follow us on Twitter or LinkedIn for updates. Get in touch if you're keen to learn more, discuss synthetic data strategies, explore use-cases, or join us in building worlds for Earth and beyond!
P.S. — If you’re interested in seeing our synthetic data in action, stay tuned — we’re announcing something fly really soon! ✈️









