
82%
overall performance took one engineer just two working days.
Overview
We developed a vision model that detects sailboats and buoys in coastal environments from an Unmanned Surface Vehicle (USV) perspective. With only 2500 synthetic images for training and 2 training runs, the model reached 82% F1 on a publicly-available real test sequence. This progress took one engineer two days using a single desktop GPU. Data downloads are available in the YOLO format.
Resources
Duration
2 days
Team
1 engineer
Compute
1 x Desktop GPU
Iterations
2
Training data
Synthetic
Test data
Real



Method
Our objective was to train a simple model to detect and classify sailboats and buoys purely with synthetic data. Performance was measured against a target sequence in the publicly-available MODS dataset containing only sailboats and buoys. We generated a total of 2500 synthetic images for training.
Also read:
Check out our curated list of maritime datasets for building robust perception models.
Creating realistic synthetic images
In general, it takes about 1000 instances to learn a new class. Using the Bifrost platform, we first generated 2000 images of sailboats and buoys, and later added 500 more.
We selected the Port City and Lake environments and applied sensor profiles similar to the footage captured in the MODS dataset.
We selected a few sailboat and buoy assets from the hundreds of assets in the Bifrost asset library. For increased diversity, camera movement, lighting and atmospheric conditions were randomized using the Bifrost platform.

Training and testing
Starting from pretrained weights, we first retrained a YOLOv11n model on 2000 synthetic images. The model converged fairly quickly, completing 40 epochs within 30 minutes on a regular desktop GPU.
Learning and detecting our new sailboat and buoy classes was incredibly easy for this first model, breaking 70% F1 on the first attempt.
But there was a glaring pitfall: it consistently failed to detect a particular kind of horizontal, oblong buoy. The model likely lacked sufficient training examples of oblong buoys, resulting in missed predictions.
Fortunately, we didn't need to collect more real-world data—an otherwise expensive and time-consuming process. Instead, we generated 500 more diverse, high-quality synthetic images containing oblong buoys to add to the training dataset.
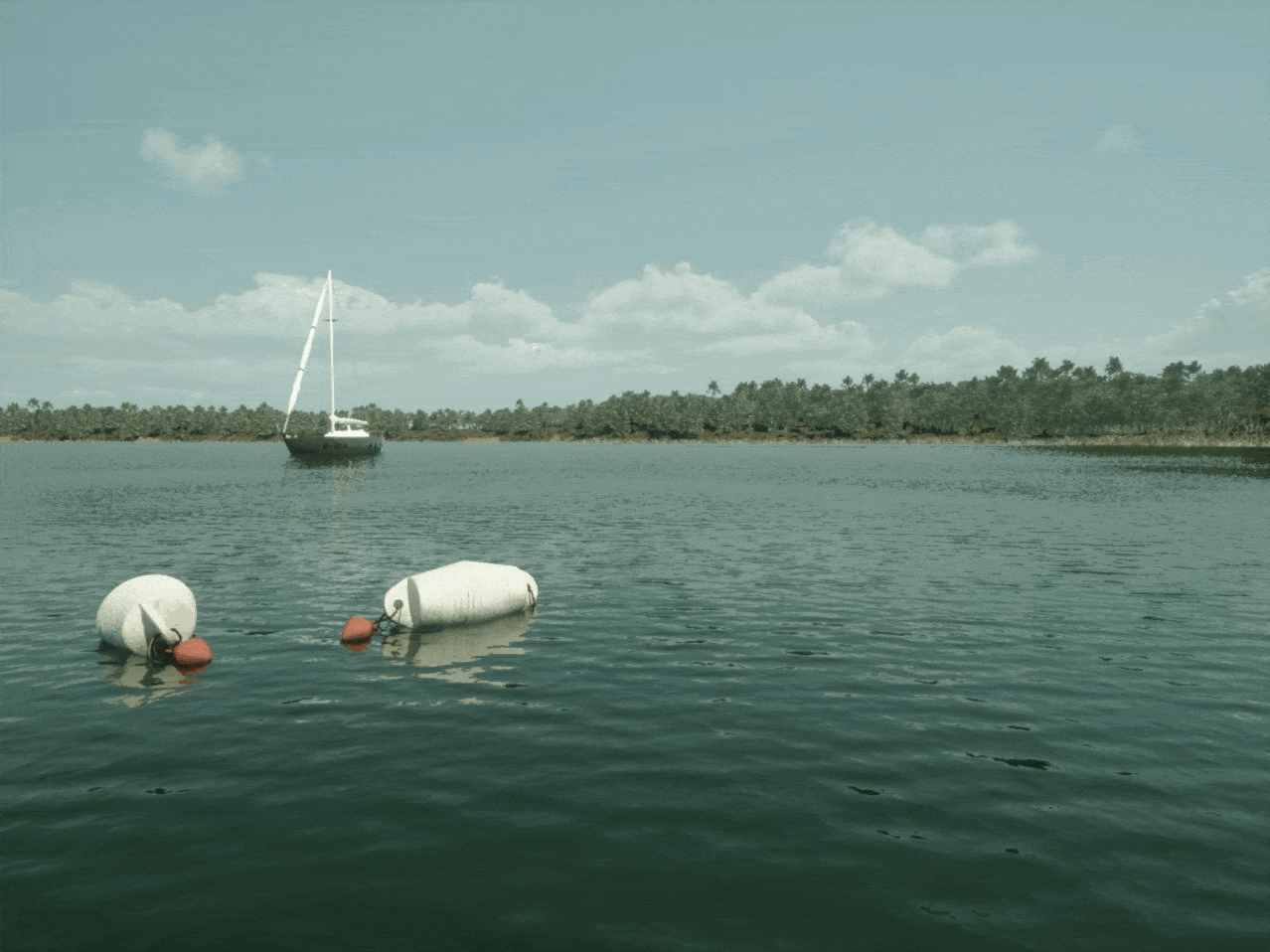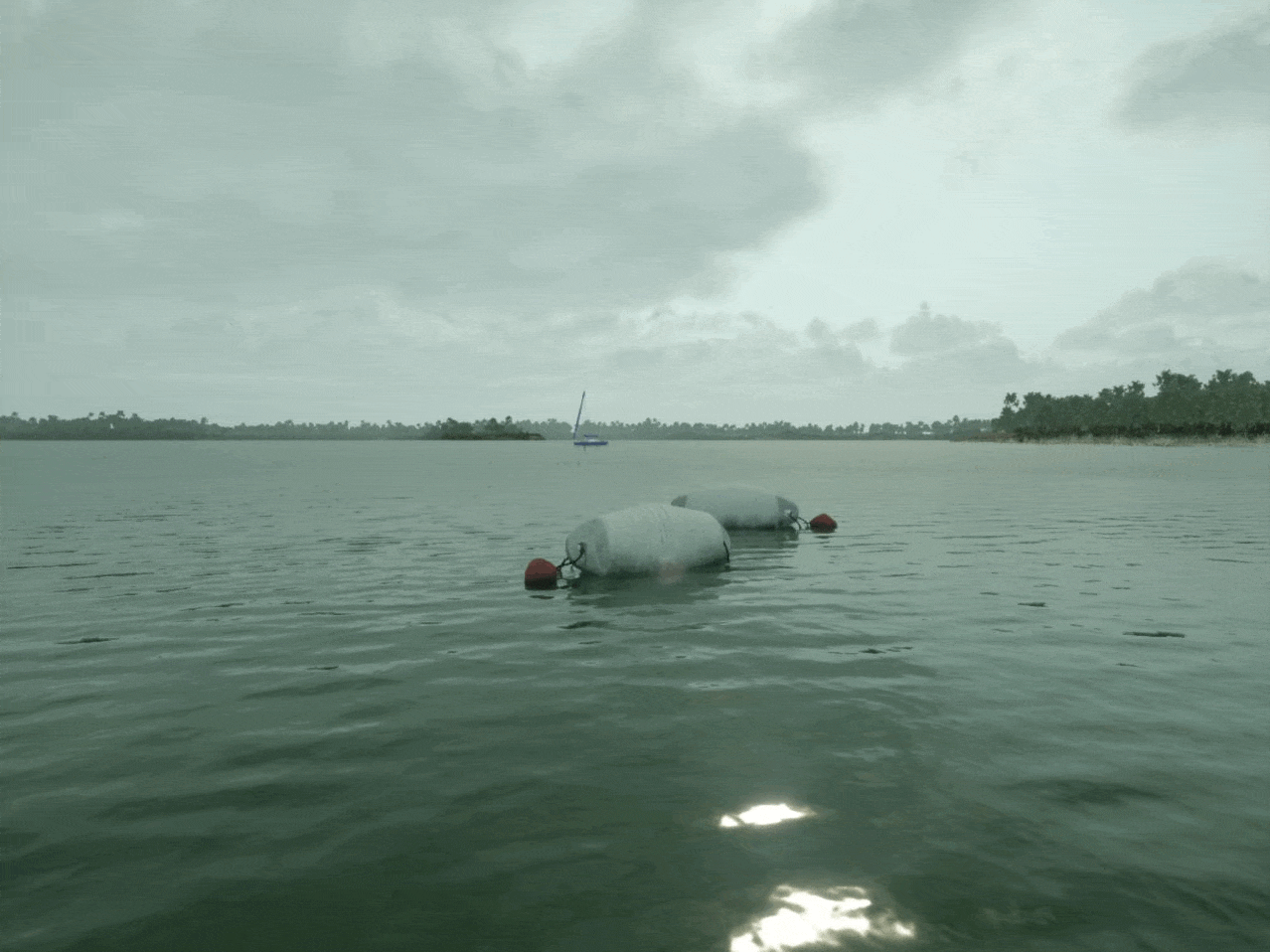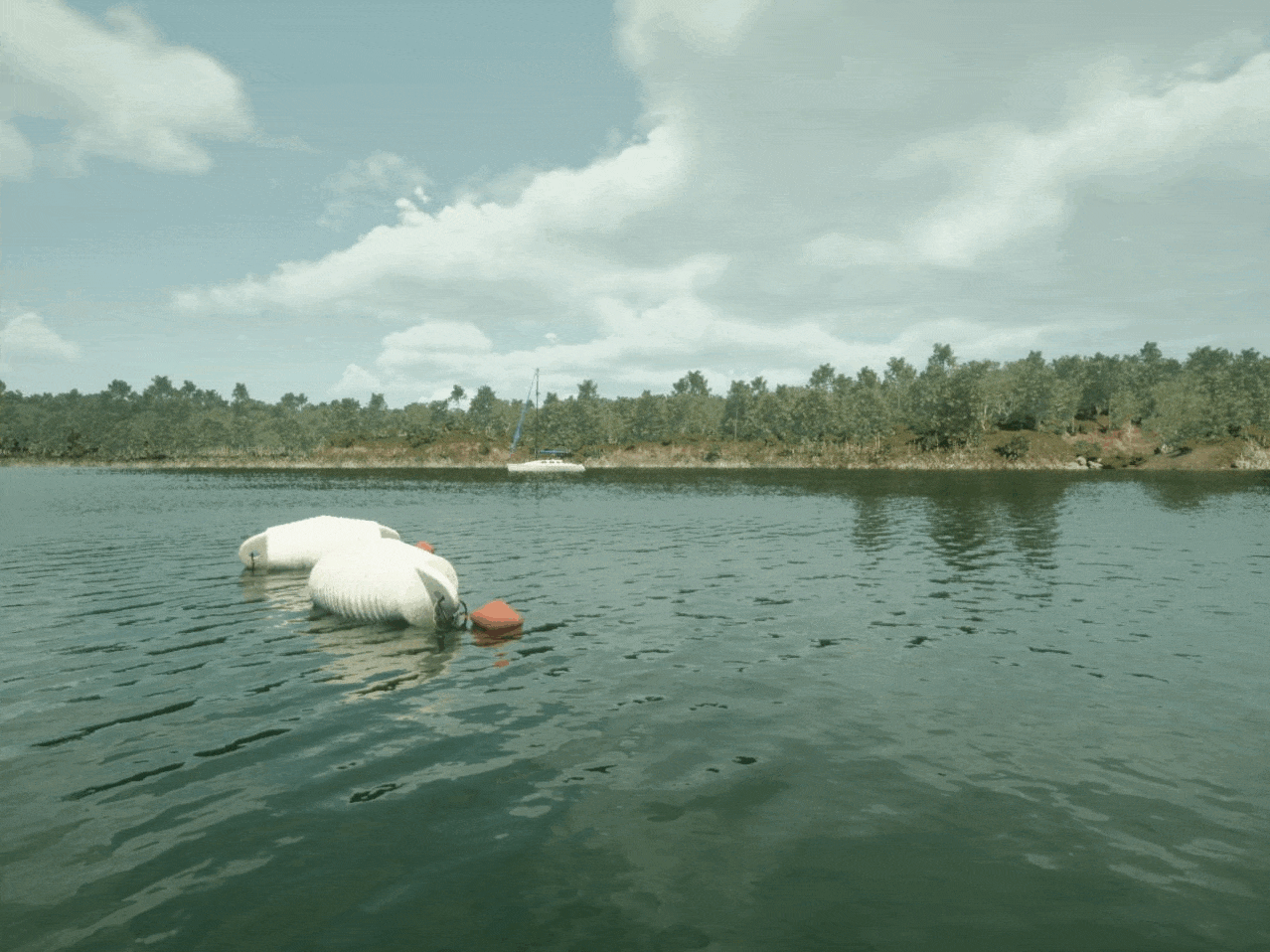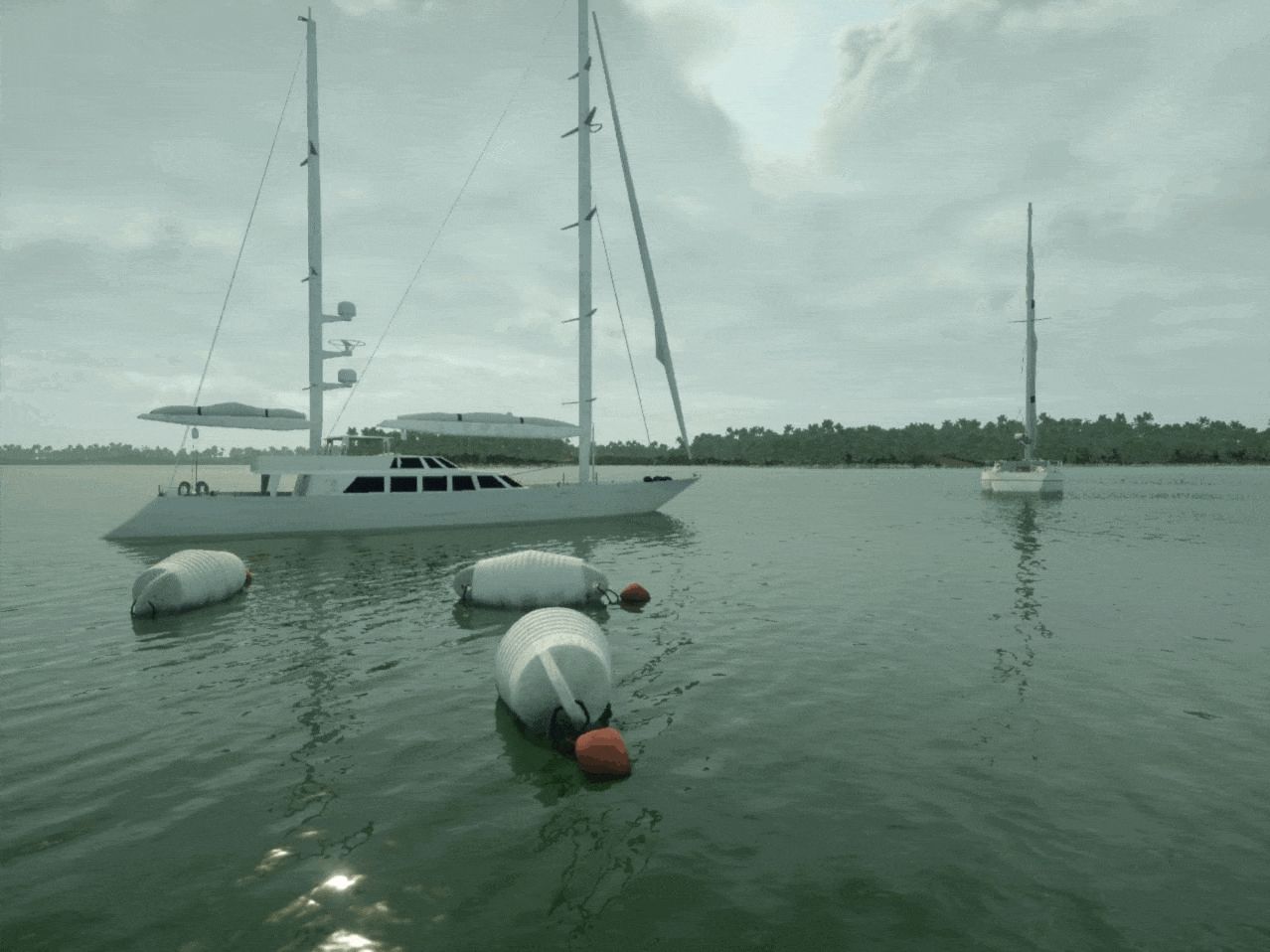
We then retrained the model using this enriched dataset, carefully monitoring for any trade-offs in performance. This time, our model's F1 improved to 82%, with most of the oblong buoys now caught.
The following video shows the inference results of the final model.
Further improvements
We note that in the test sequence, some small buoys and distant sailboats are missed. This can be fixed by generating another patch of distant buoys and sailboats, followed by retraining the model - all in an afternoon's work!
Synthetic data is a powerful tool for improving class-specific model performance. Further improvements can be made by systematically identifying failures and fixing them with synthetic data in a process we call patching.
Model improvement now takes hours, not weeks to months - made possible with thousands of high quality assets and endless combinations of sensor configurations, lighting, weather, and maritime environments. Reach out to us and learn how you can integrate synthetic data into your model improvement workflows!



