Selecting the Correct Class Label Ontology
September 07,2023
By the end of this article, you'll be able to answer the following:
- Why selecting the correct class label names plays a key role in a high performance computer vision model?
- When issues in class labels exists and how to determine the correct labelling ontology?
- Explain to stakeholders, 'How your ontology was selected?' and 'How to add more class labels if needed?"
Ontologies explained
The Oxford dictionary defines the word ontology as, “a set of concepts and categories in a subject area or domain that shows their properties and the relations between them.” In layman terms—an ontology describes how a computer vision model will name the objects it detects. Things can get tricky because an object could be described in multiple ways! For example, Americans describe a canned and carbonated beverage as either soda, pop, or coke
Should a computer vision model that detects beverage cans label them as soda, pop, or coke? This will depend on the context of the problem and how the computer vision (CV) model provides business value.
Start with return on investment (ROI) and move backwards
Let’s assume that a maritime cleaning group wants to detect garbage in the ocean to understand where clean up efforts should be focused. In the case of soda, pop, or coke--the best class name would most likely be the the physical descriptor of what contains the beverage such as can since every detection of a can leads to some type of impact on the bottom line.
Physical descriptors tend to work best because they provide a tangible basis for CV detection. A model detects cans of soda, pop or coke contained with a can.

Should this be labeled as can, soda, pop, cola etc.? How a objects get labeled greatly impacts the performance of the object detection model!
🧠 Labels should always describe the object being described.
What an object does and what it looks like can differ
Ever hear the saying, “all squares are rectangles but not all rectangles are squares”? Labels operate in a similar way. People commonly want to detect an object and also interpret the meaning of the object—but the interpretation of the object does not match the physical description of the object. All objects have interpretations but not all interpretations are objects.
Commonly, boat captains need to be aware of the other vessels in their vicinity to navigate effectively. How should a CV model created to support boat captains be labelled?
Starting with ROI
Different vessels have various rights of way and other rules so understanding the type of vessel and what the rules of engagement associated with it matter. Let’s assume that captains sometimes forget these rules and need a reminder of what to do when certain types of ships enter their vicinity.
In this case, each time a ship captain makes the wrong decision it leads to a probability of accidents and insurance claims—so the ROI statement would be something such as, “a CV model that reduces the rate of accidents and insurance claims provides value through risk prevention at a rate of X dollars per accident avoided”.
Initially, using the physical descriptor method and training a model to detect a single boat class may help a captain spot vessels, but it won’t help the captain remember which decision to make. A better ontology for this situation would be to create specific labels based on the ship’s classification such as power boat, tanker, battleship, etc.
A military naval captain may have even more specific rules of engagement based on the designation of the battleship, so further classification may be necessary.
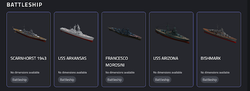
Another tricky example would be channel markers and buoys in a maritime dock setting. Buoys will often be used as channel markers to assist with navigation, but not all buoys are channel markers!
Identifying the ROI associated with the CV model plays a critical role in understanding how to properly label objects.
Why picking the wrong ontology makes model performance suck?
CV models learn by learning feature patterns, making guesses on training data, and getting score/corrected based on how close those guesses were from the ground truth labels. If two objects look visually identical, but have different class names, the model will get confused and not understand what differentiates the objects.
A CV model can only work with the pixel data it has been provided and doesn’t have an awareness of what an object will be used for—only what visual features that object has. If the buoy and the channel marker both have the same visual features (such as green and round), the model won’t perform well on that object.
How to pick the right class ontology?
CV models excel when detecting physical objects! A good general rule of thumb: if a human child can see and differentiate something a CV model should be able to as well. Pick labels that match the real world physical description of an object and layer in additional logic to interpret what to do when the object gets detected. A common solution would be to use multi-stage models to get more nuanced when required.
For example, a multi-stage flow might be:
stage 1 model: object detection model
stage 2 model: classification model
The trade off for this approach would be more accurate detections at the cost of speed and requiring additional training data for the classifier.
💡 When in doubt, label objects what they represent physically! A duck should be a duck and a boat should be a boat.
Working effectively
Nothing slows a project down like relabeling and reorganizing data. Here are few tips to keep in mind when starting a CV project:
- Fully define the scope of the CV model’s capabilities and what it needs to do to generate value
- Anticipate all possible objects that a CV model will need to detect before the labelling team gets started
- Label objects at the atomic level - this means labelling objects as granularly as possible and merging classes together as needed. E.g. Boats can be labelled as canoe, tanker, battleship and then merged into boat, but the boat class can’t be broken down in the opposite direction.
Fixing an ontology
It will always be faster and easier to pick the right ontology from the start, but experiments may show things need to change or most commonly, additional classes that create further differentiation will be discovered in the CV use case. When this happens, always make sure that:
-Changes to the label map get applied to all annotation instances
- Order of the label indexes gets preserved or mapped accordingly
- Changes made to the training data get made to the validation data, and vice versa
- Labelers have a clear understanding of which labels need to be changed and why
Ready to generate data? Create a Bifrost.ai account and start generating synthetic data today! Contact us at sales@bifrost.ai to enable access to the generative channels you need.


